

Enhancing Data Integrity and Resilience
As the digital landscape continues to evolve, the need for robust data management solutions becomes increasingly critical. Blockchain technology, known for its decentralized and immutable nature, offers a promising approach to secure data storage. One innovative technique that is gaining traction in the blockchain realm is erasure coding. This article explores what erasure coding is, how it functions within blockchain systems (especially in the “Sky Protocol”, data availability network on the Cardano blockchain ), and its advantages for data integrity and resilience.
Understanding Erasure Coding
Erasure coding is a method of data protection that transforms original data into a larger set of encoded data fragments. This process involves splitting the original data into multiple pieces and adding redundancy by generating additional fragments. The key advantage of erasure coding is that it allows the original data to be reconstructed from a subset of the total fragments. For example, if data is divided into 10 pieces and encoded with 4 extra pieces, any 10 of the 14 pieces can be used to recover the original data.
The Role of Erasure Coding in Blockchain
In the context of blockchain, erasure coding serves several important purposes:
- Data Integrity: By distributing encoded fragments across multiple nodes in a blockchain network, erasure coding enhances the integrity of the data. Even if some nodes fail or go offline, the original data can still be reconstructed from the remaining fragments. This redundancy is vital for maintaining trust in decentralized systems.
- Fault Tolerance: Blockchain networks often consist of numerous nodes that can become unavailable due to hardware failures, network issues, or malicious attacks. Erasure coding provides a fault-tolerant mechanism, ensuring that the data remains accessible and recoverable despite node failures.
- Efficiency in Storage: Traditional replication methods involve duplicating entire datasets across multiple nodes, which can lead to significant storage inefficiencies. Erasure coding allows for more efficient use of storage resources by minimizing the amount of data that needs to be duplicated while still providing high levels of redundancy.
- Scalability: As blockchain networks grow, managing and storing vast amounts of data becomes a challenge. Erasure coding can help improve scalability by reducing the overall storage footprint while still providing strong data protection. This is particularly beneficial for large-scale applications where data size and accessibility are critical factors.
Technically, we implemented Reed Solomon erasure coding to Sky protocol, it operates on a block of data treated as a set of finite-field elements called symbols and is able to detect and correct multiple symbol errors. it has many applications, one of them is storage systems such as RAID5 as will be explained later.
In this article, we need a practical example of the data availability layer to compare Sky protocol (DAL on Cardano) with it, and that is Celestia on the Ethereum platform.
Let’s see how Celestia implements erasure coding
Data availability proofs are built on a technique known as erasure coding, which takes the current block data and expands it. For example, a 1MB block can be extended to 2MB of data. The extra space in this block is filled with erasure code, which in this case, allows the entire block to be recovered as long as 50% of it is available. This means that if a malicious block producer wishes to omit a specific portion of the block, they will have to omit 50% of the block since any specific portion will be recoverable as long as 50% of the data is available. With this in mind, nodes are able to request random small portions of the block to verify if the data is available. If they fail to receive the requested portion, they can conclude that their requested portion is part of the 50% omitted by the block producer. More importantly, by taking multiple random samples, the confidence that all the data has been published can be increased from 50% with one request all the way to more than 99% certainty with just seven requests. Through data availability proofs, Celestia is able to ensure data availability for any chain that builds on top of Celestia. With this data, validators can agree on and order the transactions received, thereby providing consensus. Unlike most other chains, the validators are not concerned if the transactions are valid or not though. The rollups built on Celestia handle that independently via their own nodes.
The Celestia may have resistance to a 51% attack. However, the Ethereum network does not directly follow DAS executed on the Celestia network; instead, it verifies DAs for L2 transactions by querying DA bridge contracts located within Ethereum. If a 51% attack were to occur on Celestia, the attacker could gain the authority to manipulate the DA attestation data stored in the bridge contract through the majority of malicious validators under control. In this case, if L2 contracts send queries to the bridge contract for DAs, corrupted responses could be returned, leading to a situation where DAs cannot be ensured in L2 roll-ups.
This problem is because Celestia did not focus on data availability and focused more on security (the dishonest node always knew the data; the problem is it withholds it).
If your design doesn’t provide much-decentralized security, you may as well go centralized and at least enjoy the performance. Having a centralized DA independent from the chain operator isn’t even a bad design in the short run: separation of powers is a well-known trick that does work… for a short while, until the separated powers that be inevitably collude and/or are captured by a same Establishment.
Checking the problems of Celestia’s DA layer
The problems with Celestia’s current “data availability sampling” are:
Checks knowledge, not availability (the dishonest node always knew the data; the problem is it withholds it)
- Comes too late. Can your client tell you got hacked? Too late your coins are gone.
Instead,
- Checks must be done by other nodes within the overseeing consensus that will slash the stakes of bad actors
The usage pattern of checkers must be indistinguishable from that of validators or the attacker can trivially fake honesty.
Also if the operator pulled the rug, you don’t need any fancy availability sampling at all to find out that the tokens are gone.
Now Let’s see how Sky protocol implements erasure coding
In a very abstract way, we solve the same problem as Celestia, but we do it somewhat differently in several dimensions.
Security aspect, we fix some issues with Celestia, its “data availability sampling” that does too little too late and erasure coding algorithm that only protects against 1/4 or 1/9 attacks instead of 1/3 attacks.
- Business aspect, we solve the issue of autoscaling, wherein we offer a DEX for block space where supply meets demand, instead of having a fixed supply that grows by hard fork.
What we are talking about here is erasure coding, and we have solved the problem of 1/3 attacks with the RAID5 storage system scaling which works such that 2 out of 3 chunks are required to reconstruct the original. When users need to access their data they reconstruct it from 2 out of 3 servers But in Celestia, the ratio of these numbers is 3 to 4, which caused the problems mentioned earlier.
RAID 5 consists of block-level striping with distributed parity. Unlike in RAID 4, parity information is distributed among the drives. It requires that all drives but one be present to operate. Upon failure of a single drive, subsequent reads can be calculated from the distributed parity such that no data is lost. RAID 5 requires at least three disks.
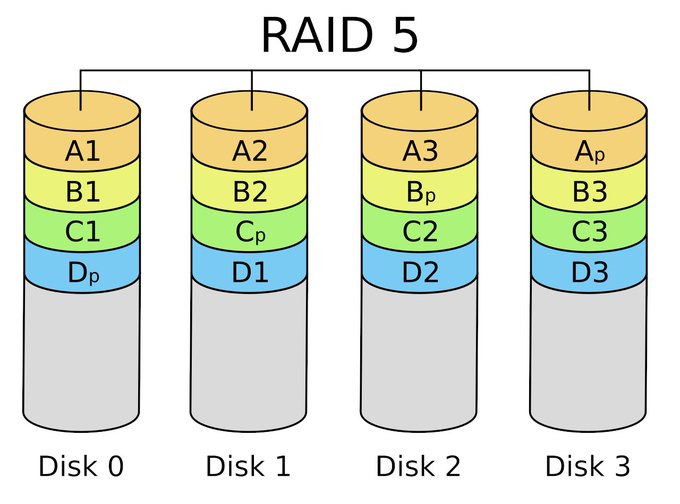
RAID5 system